A Digitális Örökség Nemzeti Laboratórium a Qulto szoftverfejlesztőivel együttműködésben egy olyan hardver- és szoftverinfrastruktúrát hozott létre, amely lehetővé teszi a nemzeti kulturális örökség mesterséges intelligencia alapú feldolgozását, kutatását, oktatását és közzétételét saját fejlesztésű, magyar nyelvre optimalizált nyelvfeldolgozó alkalmazások segítségével (DH-LAB). Mindemellett a Qulto kutatástámogatás vonatkozású termékfejlesztéseinek köszönhetően egy olyan termékcsomag jött létre (Qulto RI), amely a DH-LAB-bal integrálva komplex kutatói munkafolyamatok elvégzését teszi lehetővé. A DH-LAB-Qulto RI szoftverarchitektúra 2021-ben elnyerte a Nemzeti Kutatási, Fejlesztési és Innovációs Hivatal Ígéretes Kutatási Infrastruktúra (Emerging RI) minősítését.
A DH-LAB és a Qulto RI integrált rendszerek a következő komponenseket foglalják magukba:
- A Qulto Kutatási Infrastruktúra (Qulto RI):
- Digitális Örökség Nemzeti Laboratórium (DH-LAB):
- Kutatási adatok repozitálása az InvenioRDM repozitóriumban
- Tanítóanyaggal finomhangolható OCR
- Szövegek korrektúrázása és tanítómodellhez szükséges adatok mentése
- Szemantikus címkézés és indexelés, valamint szemantikai hálók képzése
- TEI XML-ek megjelenítése
- Metarepozitóriumi és TEI XML kereső
- Mesterséges intelligencia alapú HTR (kézírásfelismerés)
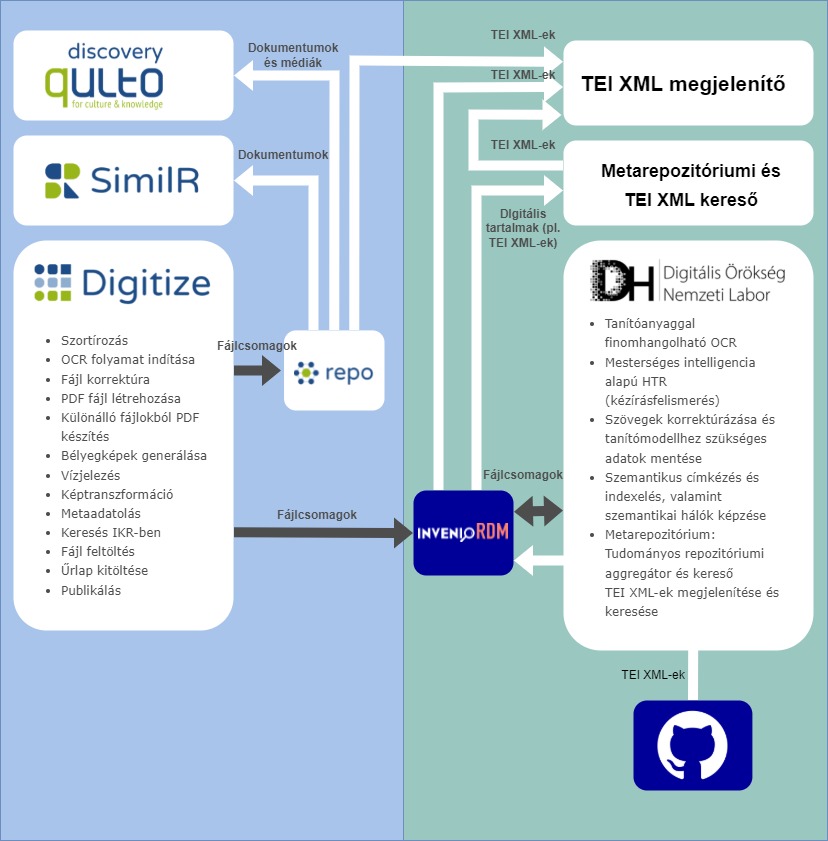
A Qulto RI és DH-LAB integrált kutatási infrastruktúra
DH-LAB: ADATREPOZITÓRIUM MESTERSÉGES INTELLIGENCIA KÉPESSÉGEKKEL
Mi az a DH-LAB?
A Digitális Örökség Nemzeti Laboratórium (DH-LAB) célja, hogy intézményközi összefogásban kidolgozza a nemzeti kulturális örökség mesterséges intelligencia alapú feldolgozásának, kutatásának, oktatásának és közzétételének módszertanát. Vállalásai között szerepel továbbá az ezen módszertanok gyakorlatba ültetéséhez szükséges hardver- és szoftverinfrastruktúra létrehozása, magyar nyelvre optimalizált nyelvfeldolgozó alkalmazások fejlesztése, anyaországi és határon túli korpuszok integrációja, valamint a magyar nyelvű born digital tartalmak megőrzése, feldolgozása és szolgáltatása.
A Digitális Örökség Nemzeti Laboratórium létrehozásában a Qulto az ELTE Digitális Bölcsészeti Tanszék szakmai partnere, és a DH-LAB digitális anyagok repozitáláshoz köthető szolgáltatásainak fejlesztésében vállal szerepet. Alapszoftverként az InvenioRDM, jelenleg fejlesztés alatt álló adatrepozitóriumi platformot használjuk.
Repozitórium és repozitálás
Az adatrepozitórium olyan infrastruktúra, amely képes digitális tartalmak (fájlok, digitális objektumok, szoftverek, stb.) tárolására, fogadására, valamint strukturálhatóvá és elérhetővé tételére felhasználók vagy más digitális infrastruktúrák részére. Az adatrepozitóriumok lehetnek (1) domainspecifikus, tehát adott formátumokban érkező adatok kezelésére alkalmas repozitóriumok, vagy (2) általános, különböző formátumú digitális tartalmak menedzselésére alkalmas infrastruktúrák. Bár a digitális bölcsészeti kutatások főként szöveges tartalmak feldolgozására épülnek, tehát domainspecifikus infrastruktúrákat igényelnek, a DH-LAB esetében ennél sokkal heterogénebb, a kulturális örökséget leképezni képes digitális tartalmak kezelésére alkalmas alapszoftvert kellett választanunk.
Annak érdekében, hogy informált döntést hozhassunk a megfelelő repozitórium kiválasztásánál, több nyílt forráskódú repozitóriumot tártunk fel az alábbi szempontok alapján:
- Fejlesztő szervezet
- Licensz
- Készültségi szint
- Dokumentáltság szintje
- Alkalmazási terület
- Integrálhatóság
- Metaadat-kezelés
- Szemantikus adatok kezelése
- Keresés és böngészés (Discovery)
- Telepíthetőség
- Autentikáció
- Architektúra
A Islandora, a DSpace 7, a Dataverse és az InvenioRDM tesztelése után arra a következtetésre jutottunk, hogy céljaink elérése szempontjából az InvenioRDM nyílt forráskódú repozitórium a legmegfelelőbb eszköz.
Az InvenioRDM az Európai Nukleáris Kutatási Szervezet, a CERN fejlesztése, tehát egy megbízható, nagy mennyiségű adat kezelésében tapasztalt szervezet terméke. Az InvenioRDM szabadon felhasználható, böngészést és facettás szűrést lehetővé tevő repozitórium, amely az Invenio Framework fejlesztői környezetben a Zenodo nevű szoftver sajátosságaira épít. Ez utóbbi kettő pontos dokumentációval rendelkezik. Metaadatolás terén az Invenio “szakterület agnosztikus“, ezért a DataCite sémát használja, ami kompatibilis egyéb metaadatsémákkal. REST API-val rendelkezik, OAuth2 autentikációt használ, és az architektúrája (React Frontend, ElasticSearch, PostgreSQL, RabbitMQ, Redis) olyan környezetben fejleszthető, amelyhez a Monguz/Qulto rendelkezik a megfelelő fejlesztői tapasztalattal. Mivel a fejlesztésénél kiemelt szempont volt a CERN részéről, hogy az InvenioRDM-ben tárolt kutatási adatok könnyen hivatkozhatóvá váljanak, a DOI szám kiosztás és ezzel párhuzamosan a verziókezelés a végleges verzió alapfunkciói lesznek, melyek szintén fontos szempontok voltak az Invenio melletti elköteleződésünkben.
DH-LAB fejlesztések
Egy egyszerű data storage-tól vagy egy alacsonyabb szintű data lake-től az különböztet meg egy adatrepozitóriumot, hogy az utóbbi különböző funkciókkal és szolgáltatásokkal (service) ellátott rendszer, melyek a felhasználás területétől függően különbözőek lehetnek. Általános repozitálási igények a fulltext kinyerése, tárolása és kereshetősége, a metaadatolás lehetősége, valamint a rekord- és rekordkapcsolat-kezelés. Bár az általunk kiválasztott InvenioRDM mindezekre képes, vagy a végleges verzióban képes lesz, a kulturális örökség kezeléséhez és feldolgozásához számos olyan szolgáltatásra is szükség van, amelyeket az alaprendszer mellé külön kell fejleszteni. Eddig az alábbi fejlesztésekkel gazdagítottuk az InvenioRDM alapfunkcióit:
- Másodlagos GUI
- Batch adatgazdagítás (t.k. kívülről nagy mennyiségű adat / metaadat bevitele file dialogból vagy command-line-ból)
- OCR szolgáltatás
- Korrektúra szolgáltatás
- Szemantikai indexelés és háló képzése metaadatokból
- Metaadatok kiolvasása TEI headerből
- TEI XML megjelenítés
Másodlagos GUI
Annak érdekében, hogy a még fejlesztés alatt álló InvenioRDM-be semmilyen fejlesztést ne vigyünk be, és így a különböző release-ek / későbbi verzióváltások ne igényeljenek folyamatos fejlesztői beavatkozást az alaprendszerben, az Invenio köré épített szolgáltatásokat egy ú.n. másodlagos felhasználói felületen (GUI) gyűjtöttük össze. A felhasználó számára így lehetővé vált a repozitóriumban lévő rekordok és fájlok online manipulációja anélkül, hogy ehhez a felhasználónak külső eszközöket kelljen igénybe vennie. A másodlagos GUI felületéről elérhető szolgáltatások a következők:
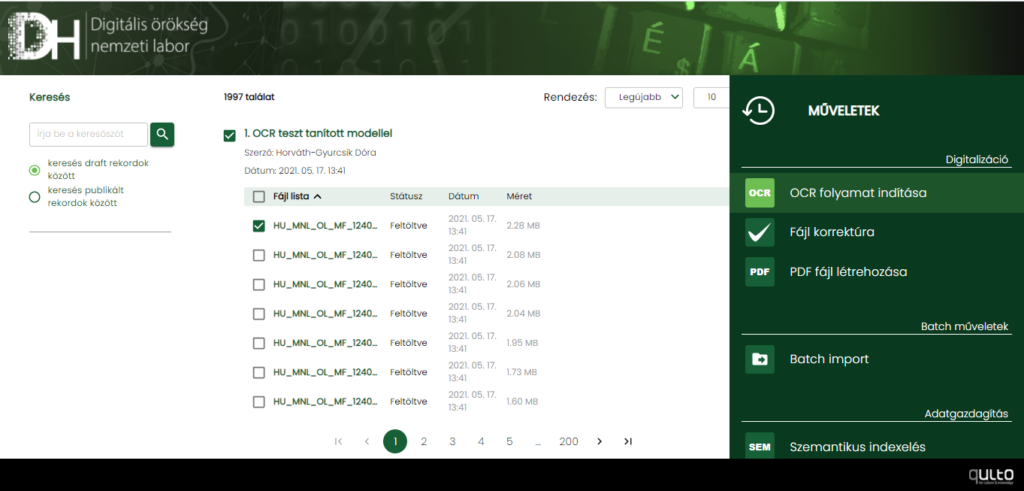
OCR szolgáltatás
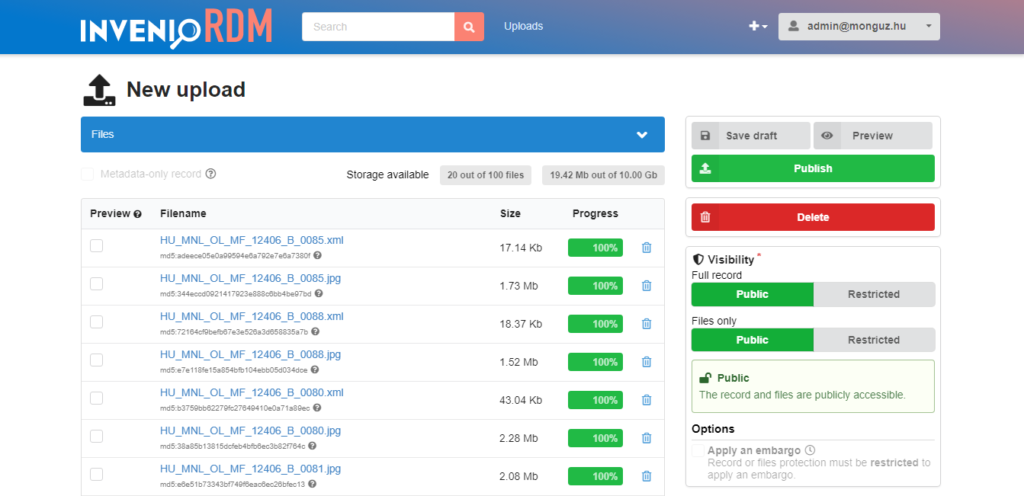
Képfájlok OCR-ezését a fájlok kijelölése után tömeges műveletként is el lehet elindítani a jobb oldali lebegő (floating) menüből.
Beállíthatjuk a karakterfelismeréshez használt nyelvi alapmodellt (magyar, angol, német) és a feldolgozás részletességét (gyors vagy részletes).
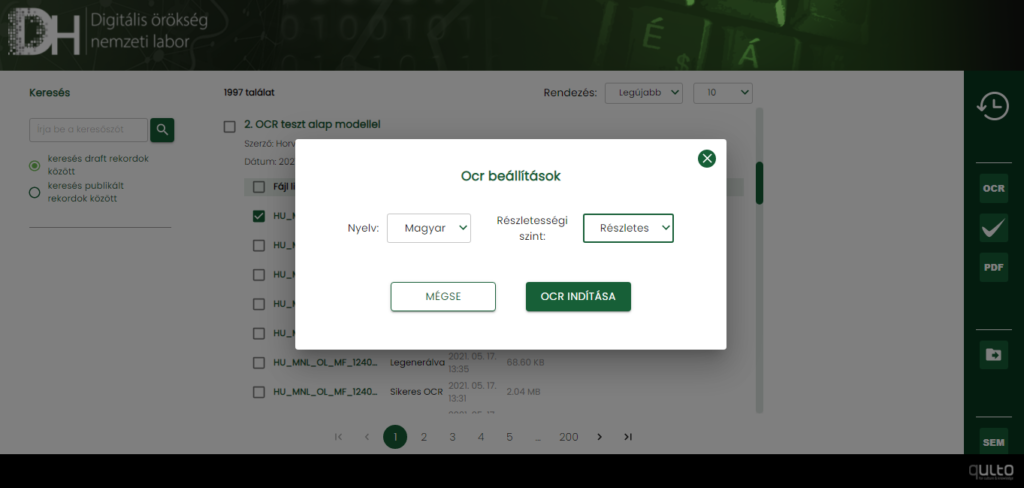
Ekkor a backend sorrendbe rendezi a fájlokat és átadja őket OCR-ezésre. Az OCR-folyamat státuszáról a státusz oszlop értéke értesíti a felhasználót. Ha sikeres volt a karakterfelismerés, a listában megjelenik az OCR-ezés eredményfájlja (XML), ami egyúttal bekerül az InvenioRDM-be is a megfelelő rekord alá.
A nyelvi alapmodellek (magyar, angol, német) használata mellett lehetőség van gépi tanulás alapú karakterfelismerésre is. Az OCR szoftver neurális háló alapú tanításához vagy nagy mennyiségű mintára (training data) épülő új modell képzésére van szükség, vagy a meglévő nyelvi alapmodell kiegészítésére. A tanításra szánt adatok előállítását mindkét esetben a következő pontban tárgyalt korrektúra eszközzel lehet előállítani.
Tehát a gépi tanulással támogatott karakterfelismerésre alapvetően két lehetőség van:
- Finomhangolás: Meglévő modellt tanítunk saját adatokkal. (Ez használható például új betűtípus megjelenése esetén.) Kis mennyiségű tanító adattal is működhet.
- Új modell építése az alapoktól: Nagyon sok tanító adat kell hozzá. Ha kevés adattal tanítunk, akkor a modell csak a tanító adatokra fog illeszkedni, melyekre jól hatásfokkal fog működni, de más adatokra nem.
A tanító folyamat lépései:
- Tanító szövegek előkészítése
- Kép és box fájl (utóbbi opcionális) készítése a tanító szövegből
- Unicharset file készítése
- Kiindulási traineddata készítése (új modell építéséhez) vagy meglévő használata (modell kiegészítéséhez)
- Új tanító adatok készítése (opcionális)
- Tanítás futtatása a tanító adatokon
- Elkészült modellek kombinálása (opcionális)
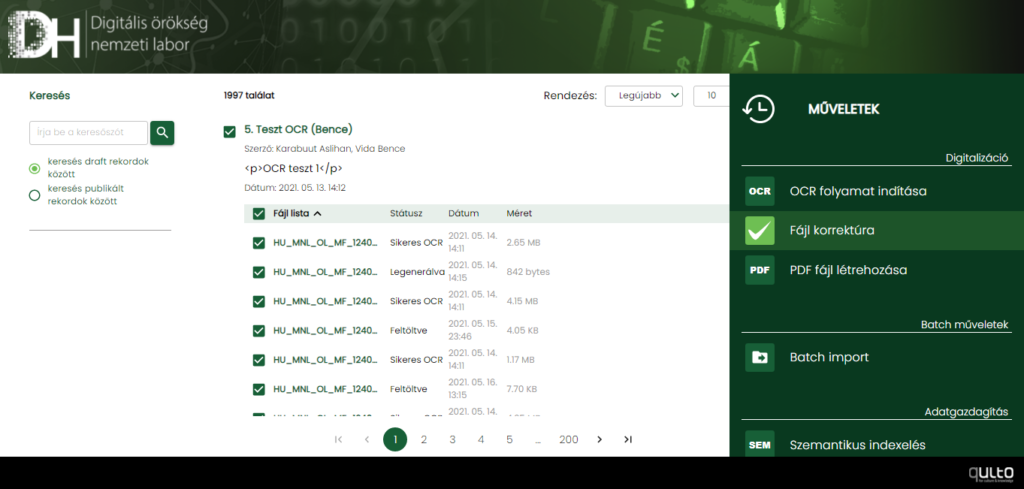
OCR eredményfájlok korrektúrázása
Lehetőség van az egy rekordhoz tartozó OCR eredményfájlok (ALTO XML) javítására a rekord kijelölésével és a folyamat elindításával a jobb oldali menüben.
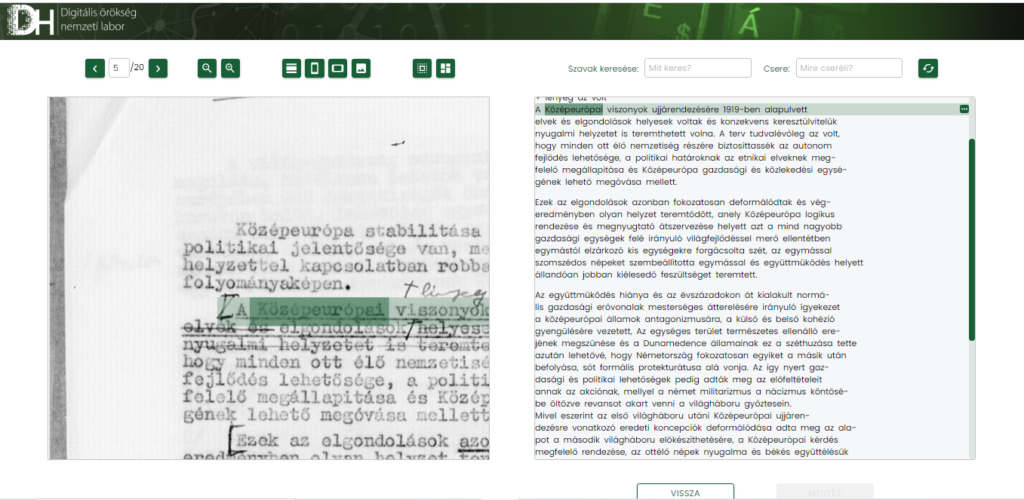
A rekordhoz tartozó fájlok lapozható nézetben megjelennek a korrektúrázó felületen, ahol a képi és a szöveges rétegben történő navigálás szinkronban van egymással — t.i. A szoftver kiemeléssel jelzi az adott string helyét a képi rétegen. Blokkok, sorok és szavak létrehozására (ha az OCR eszköz nem ismerte fel őket) és javítására a bal felső menü és inline műveletek segítségével van lehetőség.
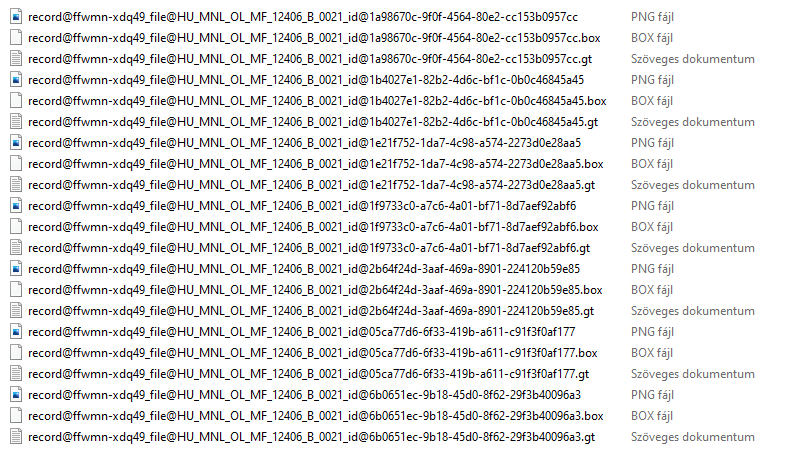
A felhasználó a javítások mentésével nemcsak a javított XML-eket menti vissza a repozitóriumi rekordhoz, de az OCR eszköz számára training set-eket is előállít. Egy javított szó esetén három fájl generálódik egy dedikált mappába: a szó körülvágott képfájlja (PNG), egy szöveges dokumentum, amely a szót tartalmazza, és egy BOX fájl, ami az adott szó egyes karaktereinek a koordinátáit tartalmazza. A későbbiekben az OCR eszköz ezeket a fájlokat tudja felhasználni gépi tanulásra és így a karakterfelismerés hatásfokának javítására.
PDF létrehozása
A képi réteg és az OCR folyamat eredményeként elkészült ALTO XML fájl összeillesztése az eredeti képfájlok és a hozzájuk tartozó XML-ek kijelölésével. Az eredményfájl egyúttal kapcsolódik a vonatkozó repozitóriumi rekordhoz.
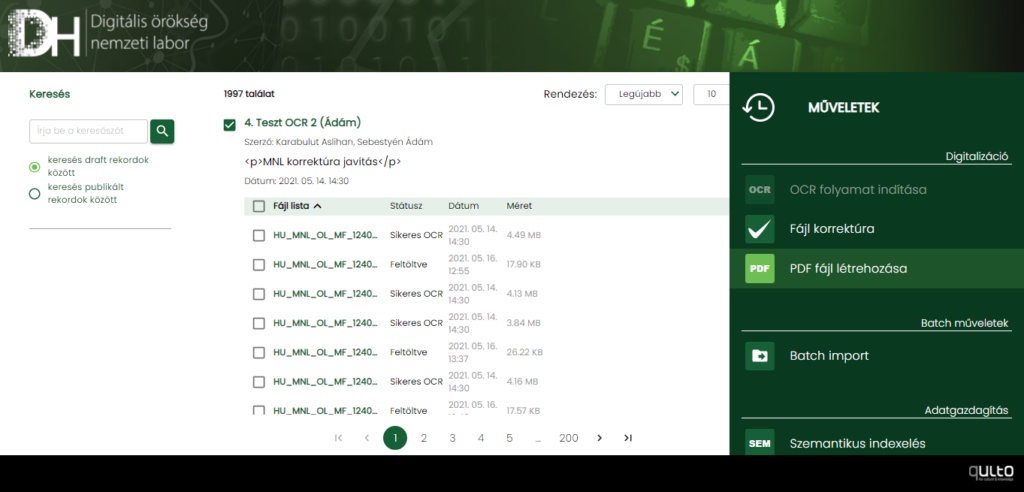
Batch import
A másodlagos GUI-ról lehetséges fájlok és a hozzájuk tartozó metaadatok tömeges feltöltése az InvenioRDM-be.
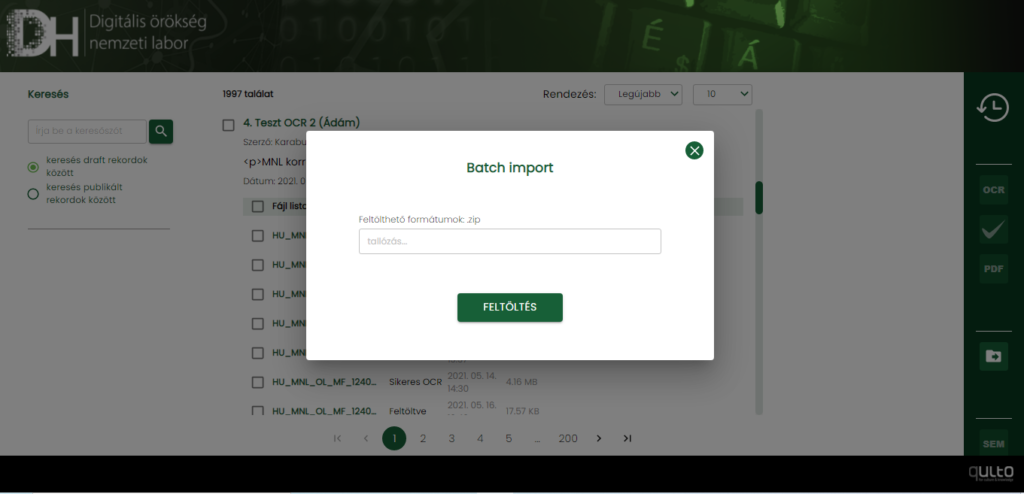
Egy felnyíló dialógus ablakon keresztül tallózhatunk ZIP fájlokat, melyek tartalmazzák a könyvtárstruktúrába rendezett fájlokat rekordonként, valamint a könyvtár gyökerében az ezekhez tartozó metaadatokat egy CSV fájlban. Az anyagok összeállításánál közös mappába kell rendezni az egy rekordhoz tartozó fájlokat, így akár hierarchikus rekordkapcsolatokat is leképezhetünk. Feltöltés után a rekordok a vonatkozó metaadatokkal és kapcsolódó fájlokkal együtt megjelennek az InvenioRDM repozitóriumban, és így természetesen a DH-LAB felületén is.
Ugyanerre a műveletre lehetőség van konzolból, betöltőszkript segítségével is.
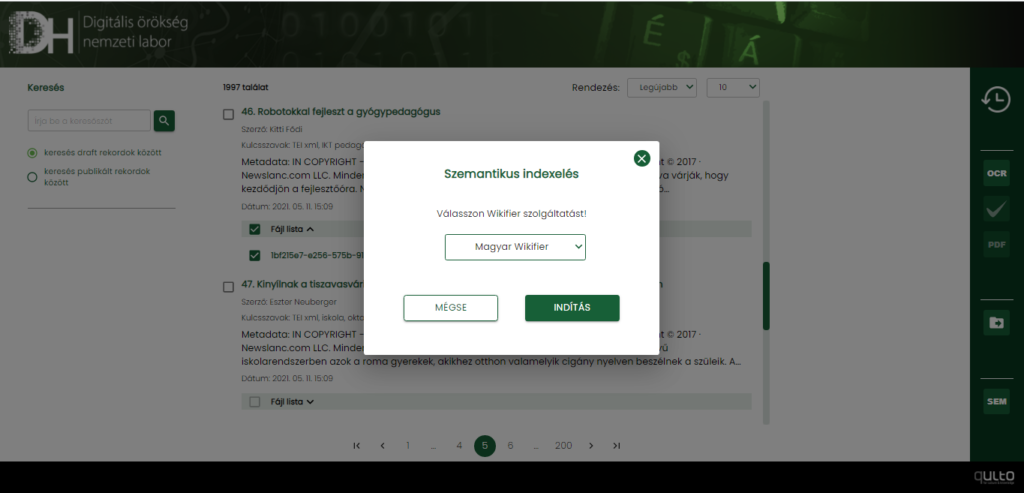
Szemantikus indexelés
Szöveges tartalmak szemantikus feldolgozását a szöveges fájl kijelölésével és a lebegő menüben található Szemantikus indexelés ikonra kattintva indíthatjuk el.
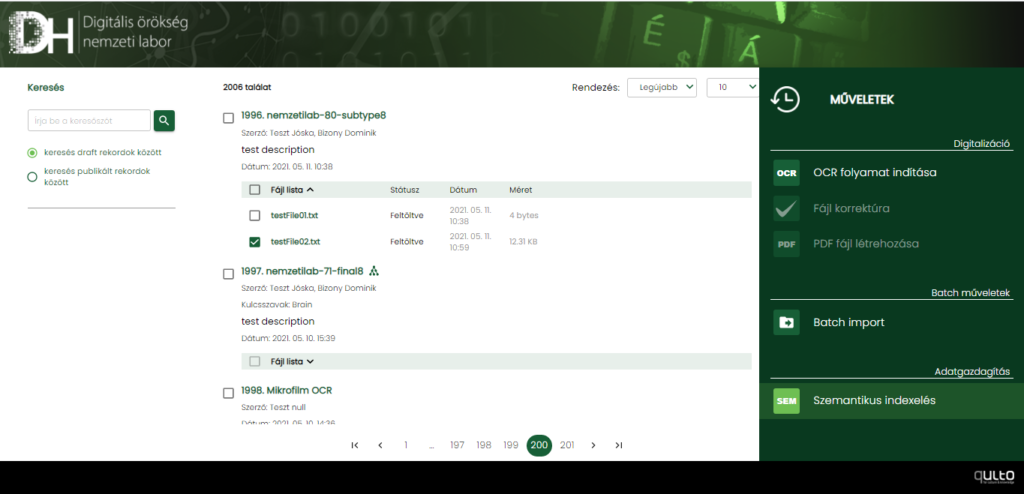
Ezután egy dialógusablakon a felhasználó kiválaszthatja, hogy magyar vagy angol nyelvű Wikipédia entitásokkal kívánja-e összevetni a szöveg tartalmát.
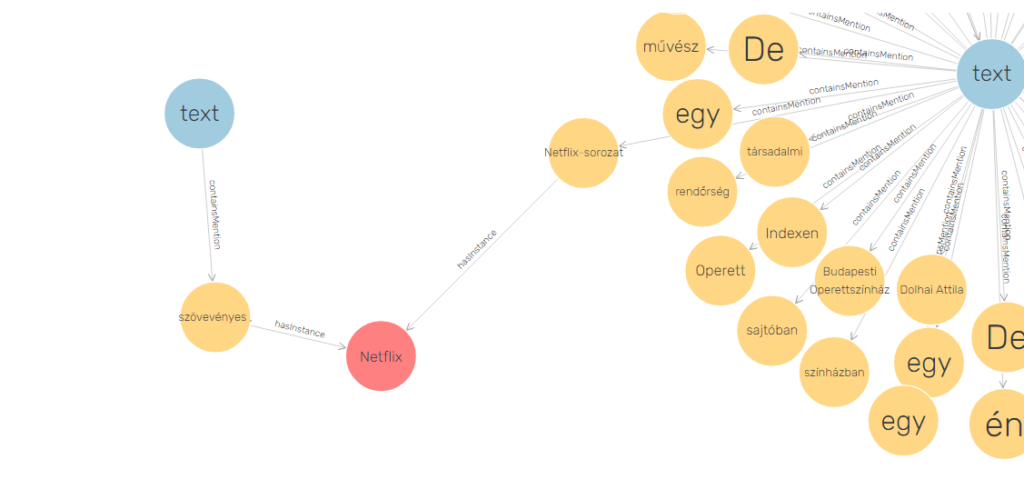
Ezzel megtörténik a szövegben a Wikipédia entitások beazonosítása, majd az entitások, mint csomópontok élekkel történő összekötése — ezáltal állításokat kapunk. Így például a szöveg csomópontból az egyes entitások containsMention élekkel kapcsolódnak, tehát a szöveg említi a vele összekötött entitást (ebben az esetben szó vagy kifejezés). Összetett szavak hasInstance éllel kapcsolódnak az összetett szó Wikipédia entitásként létező eleméhez (pl. Netflix-sorozat).

TEI XML-ek megjelenítése
A digitális bölcsészet filológiai és irodalomtörténeti kutatás szempontjából fontos vállalása a párhuzamos szövegváltozatok digitális eszközökkel történő feldolgozása. A kötött kódolási konvenciókat meghatározó és követő Text Encoding Initiative (TEI) olyan módszertant bocsát a szövegvariánsok sajátosságainak rögzítésére, amely a párhuzamos tanúszövegek (witness) tárolását egyszerűen és digitális eszközökkel történő elemzését széles körben teszi lehetővé. A feldolgozás eredményfájljai (TEI XML) azonban csak erőforrásigényes fejlesztési munkával tehetők emberi befogadásra alkalmassá. A DH-LAB és a Qulto által megvalósított TEI XML megjelenítő a végfelhasználó számára értelmezhetővé és kutathatóvá teszi a magyar irodalmi kánon legjelentősebb alkotásainak párhuzamosan létező szövegváltozatait.

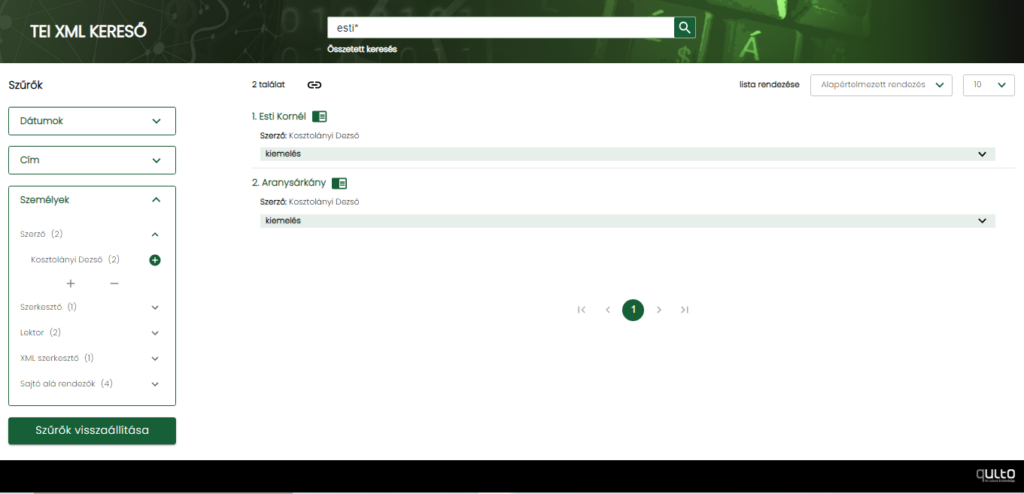
TEI XML-ek keresése
A TEI XML-ek keresését egy univerzális és a keresendő tartalmakra konfigurálható keresőmodullal tesszük lehetővé. A keresőeszköz a GitHubbal, az InvenioRDM-mel és a Qulto Repóval integrált keresőmotor, amely lehetővé teszi a TEI XML-ekben kódolt metaadatok alapján történő keresést és szűrést, de egyéb, például repozitóriumokban és verziókezelőkben tárolt digitális formátumok keresésére egyaránt alkalmas.